
This document serves as the entry point to the current state of discussion in the group cbXML. It should guide the further debate and is envisaged to evolve to become the Gesmes/CB-XML format specification. Still, it has no formal status.
This document is provided as is and without any warranties. In no event can the author or an institution he is affiliated with be made responsible for any kind of damages connected to the use of this document, however such may be caused.
This document contains links to destinations which are not under the control of the author. Neither the author nor any institution that he is affiliated with can take responsibility for the content of any resources linked to. It is the plight of the user of this document to make a deliberate and appropriate selection when following links and be aware of the risk that the content linked to does not live up to the expectations.
This document may contain registered words and trademarks without individual mentioning. This fact cannot be construed as a claim that these expressions are free of rights of third parties.
You must not use this document and must immediately delete it unless you accept this disclaimer.
User requirements have been collected using a Questionnaire, which was distributed to all members of WGSIS and GMWG and also some other institutions. All responses were collected in the Stories Database. Knowing the audience, it is not surprising that most emphasis was given to requirements which help leveraging the benefits of Gesmes/CB-XML in the context of the existing business process, which can be summarised as the batch data exchange model. The aims derived from these requirements are:
EEG6/WG1 expressed their interest in the development of Gesmes/CB-XML having in mind an XML version of the Gesmes standard. This calls for:
XML nowadays is a very popular data exchange format (the second most prominent next to ASCII maybe) and is supported by a diverse set of tools.
XML is widely renowned as the format for the Web. Requirements to be prepared for the challenges from this side are:
XML has earned the reputation of being readable for humans, at least better in this respect than e.g. EDIFACT. Once a document is readable and can be understood, users may even be tempted to modify the contents here and there in a text editor. Note that with Gesmes/CB-EDIFACT, one had to be aware of the segment count and splitting strings into components of maximum lengths 70 characters. This raises the requirements to:
Finally, many people are deterred from Gesmes/CB because it is infamous for its apparent complexity; therefore:
To judge proposals, the following metrics have been proposed:
XML, the Extensible Markup Language, is a recommendation of the World Wide Web Consortium (W3C), where abundant material about XML and related technologies is held available. In this section you find a very brief description of some basic terminology used in the context of XML.
A document is a stream of characters, typically the text contained in a file, but there are transient documents, too, e.g. a message between networked applications.
A tag is a piece of markup in a document. In XML, all markup is enclosed in angle brackets "<" and ">". There are other kinds of markup than tags, too, but these are of less interest here.
An element is denoted by a pair of tags, one start tag and one end tag: <prepared>...</prepared>. The token immediately following the opening "<" (here "prepared") is the element name. The text between opening and closing tags (here symbolised by three dots) is the element content. If an element has no content (i.e. is empty), an abbreviation using only one tag can be written in place of the two tags: <test/>.
The document element is the outermost element in a document. E.g. XHTML defines the document element html, which corresponds to the well-known tags <html> and </html> at the beginning and end of an HTML-document, respectively.
An attribute is a name-value pair provided inside an opening element tag: <Envelope id="IREF000001">...</Envelope>. The attribute value must be enclosed in double or single quotes. Empty elements may still have attributes.
A namespace collects a set of elements and attributes. It is represented by a URI, which can be but not necessarily is a URL. The important thing about the URI is its global uniqueness and thus it is handy for an organisation to use a URL in the web-space it owns. Within a document, a namespace is assigned to a namespace prefix by a namespace declaration, which comes in a form syntactically similar to an attribute: xmlns:gesmes="http://www.gesmes.org/xml/2002-08-01". Once declared, a namespace prefix can label element and attribute names: <gesmes:action>update</gesmes:action>. A namespace declared without prefix (e.g. xmlns="http://www.ecb.int/vocabulary/2002-08-03/microbop") becomes the default namespace. This applies to all elements (but not attributes!) in its scope which carry no namespace prefix.
The XSLT (Extensible Stylesheet Language Translation) provides a standard mechanism to translate XML documents from one format to another. The target format need not be XML but often it is. Particularly popular is the translation to XHTML, which allows viewing XML documents in an HTML browser.
An XML document can contain a document type declaration, which specifies the document's grammar. This grammar is referred to as DTD (Document Type Definition). A DTD can restrict allowed nesting relationships between elements and the available attributes for an element. It can specify types for element content and attribute values. However, DTDs have a very limited set of built-in types.
An XML Schema, like a DTD, specifies the structure of an XML document. Actually, XML Schema is a modern alternative to DTD and overcomes many of DTD's weaknesses. Schemas are themselves XML documents and can therefore be processed using standard XML tools. In contrast to DTDs, Schemas can handle namespaces. They provide also more built-in data types, e.g. dateTime.
A document is well-formed if (among other requirements) every opening tag is closed by a suitable closing tag and nesting order is maintained: Last opened, first closed.
A document is valid if it is structured according to the DTD specified in its DOCTYPE declaration at the start. Similarly, a document can be (Schema-)valid with respect to a relevant XML-Schema.
Gesmes, the Generic Statistical Message, is an EDIFACT standard format maintained by the UN/ECE. The format Gesmes/CB has been defined as a profile of Gesmes. This means that Gesmes/CB data is also valid Gesmes but does not use all features available in Gesmes. Therefore, processing Gesmes/CB is significantly simpler than processing plain Gesmes. Additionally, Gesmes/CB uses a well-defined data model on top of the bare message syntax. It is this data model which is most interesting in the context of Gesmes/CB-XML since it describes the objects that Gesmes/CB deals with and their relationships.
In this section you find a very brief description of some basic terminology used in the context of Gesmes/CB, particularly focusing on the data model.
The analysis model of Gesmes/CB has been formulated in the UML (Unified Modelling Language). The latest available such model is called ResultDraft5 and can be retrieved from cbXML, Circa, or eRoom depending on your membership conditions. That document is quite technical, however. The core of the model is also presented in a pattern-oriented fashion at http://www.unece.org/stats/documents/ces/sem.47/22.e.pdf. This document is easier to read and close in its presentation to this Gesmes/CB-XML proposal.
One important paradigm of Gesmes/CB is the split between structure and data. Structure tells about the schematic organisation of data; data specifies the actual values.
The fundamental mechanism behind Gesmes/CB data can be derived from the minimalist idea of name-value-pairs that a name identifies a value. Only, since Gesmes/CB is about multi-dimensional data, it is several names together (called Dimension Values) which identify one or more values (called Characteristic Values). (For Dimension and Characteristic also see Knowledge level: structure.) The following diagram illustrates these relationships: Three Dimension Values on the left together identify one Characteristic Value for each Characteristic on the far right.
|
| Figure 1: Fundamental Gesmes/CB data model |
The data model expresses this simple but fundamental relationship in three steps. The Dimension Values together form a Key. This Key then identifies a Cube. Finally, the Cube carries the Characteristic Values.
 |
| Figure 2: Gesmes/CB data model using Key and Cube |
This division into steps structures the relationships more orderly because the identification relationships are now centrally handled between Key and Cube. Nevertheless, Key and Cube remain imaginary notions only introduced to ease thought, communication, and possibly processing. Be reminded of the well-known observation from mathematics:
Jacques Hadamard: The shortest path between two truths in the real domain passes through the complex domain.
Gesmes/CB defines four classes of Cubes:
In a certain sense, one can say that a Time Series includes a number of Observations, a Sibling Group includes a number of Time Series, and a Data Family includes a number of Sibling Groups. Summing up, there can be an inclusion relationship between Cubes.
Characteristics can take values only for one class of Cubes each. For instance, the "Observation Value" (a Characteristic usually called OBS_VALUE) can take values only for Observations while the TITLE may only apply to Sibling Groups. This restriction is expressed as the attachment level of a Characteristic.
Data is grouped into Data Sets. The way this is done is not normatively defined so far. However, the idea is that a Key identifies a Cube from within a Data Set, so a Data Set provides a mapping from Keys to Cubes. Physically, a Data Set could be a Gesmes/CB-EDIFACT file or a database, even a database view. The structure of a Data Set is determined by a Key Family. This Key Family specifies the available Dimensions, Characteristics, and admissible Values for these.
Structural information is expressed in terms of three kinds of Structural Definitions:
Gesmes/CB originally was conceived as a message format and thus specifies envelope information like about sender, receiver, subject, preparation time stamp. A Gesmes/CB-EDIFACT data therefore always comes in an Interchange carrying basic such information and wrapping one or more Messages carrying more such information but also Structural Definitions or Cubes depending on the message type. A significant part of the data in the envelope is just textual. But there are also structured data types used to transport sender contact information.
Like every EDIFACT message, Gesmes/CB-EDIFACT comes as a sequence of segments. Each segment starts with a three letter tag and continues until a closing apostrophe. The tag defines the syntax and basic meaning of the segment. In Gesmes/CB, the most important tag is ARR. An ARR-segment could look like
ARR++M:TT:G:200007200009:710:13.6:A+14.8:A+15.1:A'
In this example, the tag is followed by two +-signs, which function as separators. The sequence M:TT:G codes the (Time Series-) Key, i.e. the Dimension Values, separated by colons. The sub-string 200007200009:710 specifies the Time as a range of months. Then follow tuples, in which again the colon is used as a separator. There is one tuple for each Observation: 13.6:A, 14.8:A, and 15.1:A. The portion before the colon is the Characteristic Value for the Characteristic usually called OBS_VALUE. The string A is the Characteristic Value for the Characteristic usually called OBS_STATUS. The tuples could also contain optional confidentiality and pre-break values. These four Characteristics (usually called OBS_VALUE, OBS_STATUS, OBS_CONF, OBS_PRE_BREAK) are also referred to as Array Cells because the values for them are transported in ARR-segments (this is in the array section of a Message).
The values for all other Characteristics are transported in the footnote section of a Message, which consists of segments following the FNS-segment. There can only be one FNS segment per Message. The footnote section contains further ARR-segments, which carry the Keys, IDE-segments which identify the Characteristics, and either CDV or FTX segments which carry the Characteristic Values for these Characteristics:
FNS+Attributes:10' ... ARR+3+M:TT:G' IDE+Z10+UNIT' CDV+KILO' ...
These lines would mean that the Time Series identified by the Key M.TT.G has a Characteristic Value KILO for the Characteristic UNIT; in short: "M.TT.G's UNIT is KILO." If you remember the Fundamental Gesmes/CB data model, then you see that this syntax follows quite closely the pattern indicated: Specify Dimension Values, Characteristic, and the Characteristic Value for it. Only the Dimensions are not explicitly mentioned. Gesmes/CB-EDIFACT uses an ordered set of Dimensions and thus an ordered Key. Therefore, it is not necessary to refer to the Dimensions explicitly when a Key like M.TT.G is written. The reference is implicit by the position in the Key. In the same fashion, Array Cells are ordered so that there the Characteristics need not be made explicit in the array section, either.
More information and links about Gesmes/CB-EDIFACT can be found at http://www.ecb.int/stats/gesmes/gesmes.htm.
A reader less acquainted with the UML may choose to skip this section and come back after reading the Section Syntax implementation.
The implementation model of Gesmes/CB-XML is based on the analysis model as laid down in ResultDraft5.
While the analysis model of Gesmes/CB reflects human perception of Gesmes/CB and describes the objects of Gesmes/CB independent of the syntax, the implementation model of Gesmes/CB-XML defines the classes used in the XML syntax implementation. Since performance and ease of processing are issues constraining the implementation model, the two models differ in a few points. Most differences simplify the implementation model; for instance in the implementation model, there is no explicit distinction between the subclasses of Cube: Hence one class to replace four. Also see Differences from the analysis model.
The implementation model of Gesmes/CB-XML consists of five packages: data package, structure package, activity package, envelope package, and extension package. The following diagram shows their dependencies by dashed arrows. E.g. the data package relies on the structure package.
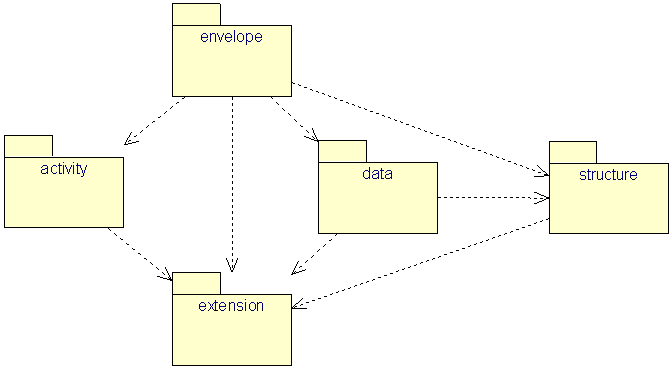 |
| Figure 3: Overview of all packages |
The data package provides the class Cube, which is at the heart of the mechanism for transport of multi-dimensional data. The structure package furnishes the data package with the necessary layout information. The activity package captures some information from the Process model. The envelope package contains the class Envelope for the XML document element, which can be wrapped around the content to be transferred. The extension package defines a simple mechanism to furnish model elements in the other packages with additional information needed in particular environments.
The following sections describe the packages of the implementation model of Gesmes/CB-XML in detail.
The data package defines the skeleton necessary for the exchange of Cubes: The classes Cube and Value. The small size of the data package reflects the desire to allow an easy implementation of Gesmes/CB-XML for all parties interested in the exchange of multi-dimensional data.
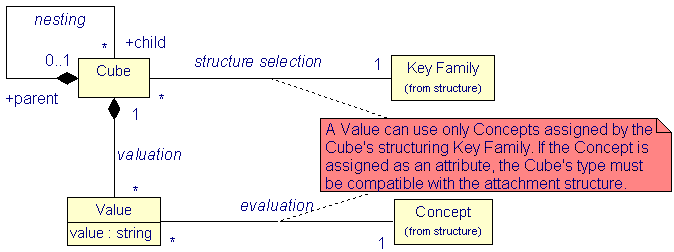 |
| Figure 4: The data package |
The essence of the package is the mechanism that Cubes carry Values for Concepts. A Key Family determines which Concepts are available. This Key Family also specifies which of these Concepts are used as dimensions and which as attributes. The combination of Values for the dimensions (the key) then identifies a Cube. The Values for attributes provide the information to this Cube.
XML has nesting as its foremost built-in association mechanism. This is modelled using the nesting association. Nesting is interpreted to imply inheritance of Values from parent to child. For more on the treatment of nesting see Pushdown model for processing Cubes.
Though in principle, the data package is simple, certain constraints are applicable. The Cube's layout is defined by a Key Family which specifies all available Concepts. In addition to that, not all Cubes can take Values for all Concepts. When a Concept is assigned as an attribute, then it may have a Value for a Cube only if this Cube has (or inherits) Values only for dimensions referenced in the attachment structure of the Concept's Attributes container. This is meant by the Cube's type being "compatible" to the attachment structure. For those familiar with Gesmes/CB-EDIFACT: The attachment structure of an Attributes object in a Key family codes an "attachment level" and the dimensions for which a Cube has Values determine the "type" of Cube.
The Gesmes/CB model of multi-dimensional data is compatible though not identical with the multi-dimensional package of OMG's Common Warehouse Metamodel (CWM). What in CWM are the values of the dimension "measure", corresponds to the Concepts used as attributes in Gesmes/CB-XML.
Gesmes/CB owes its flexibility to its capacity to transport not only data but also structural definitions; these define the data layout. The structure package assembles the classes which provide this functionality: Code List, Concept, Key Family, and a couple of others used by these classes.
It is common in Gesmes/CB to define the basic properties of a Concept in one place and later, when assigning the Concept, refer to this prototype and to fill in any necessary additional information, particularly about allowed values. In general, prototyping allows building Structural Definitions on the basis of previously defined ones of the same class. Also references are implemented using the prototyping relationship: Then simply no information is added to the referenced prototype's.
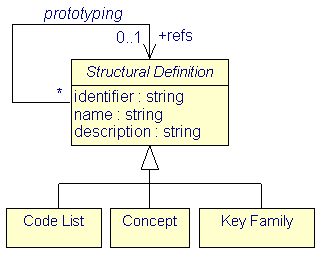 |
| Figure 5: Types of Structural Definitions |
From the perspective of partners exchanging data, the entry point into the structure package is the class Key Family. It tells an application about the Concepts which are available for building data Cubes and whether this is as dimensions or as attributes.
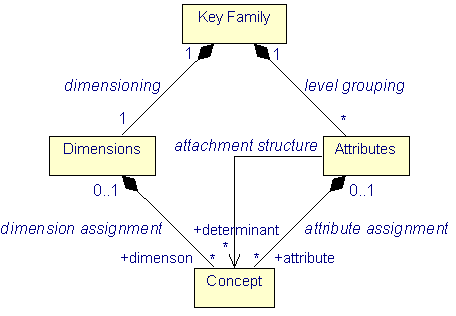 |
| Figure 6: A Key Family assigns Concepts |
Concepts can play two roles. When assigned as dimensions, i.e. as members of the Dimensions collection, they participate in the mechanism to identify a Cube. When assigned as attributes, i.e. as members of an Attributes collection, they help to furnish Cubes with descriptive Values.
An attribute Value may be logically determined by only a subset of all available dimensions. For instance, a time series title would typically not vary along the time dimension. To express this, each Attributes collection has an attachment structure link to those dimensions which are relevant to determine the Values for the Concepts it contains.
The structure package also provides a simple framework to validate and interpret Values. To this end, a Concept can choose a Value Set from a multitude of possibilities.
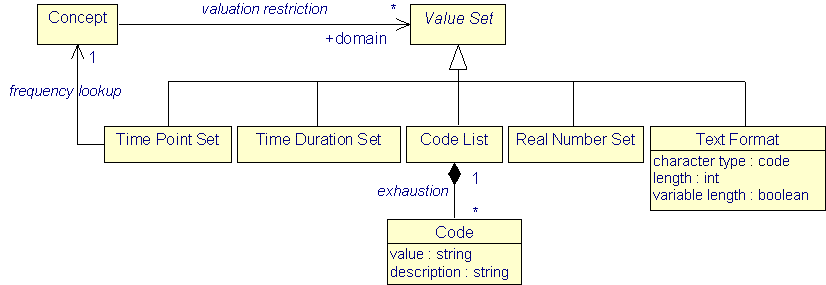 |
| Figure 7: Restricting Values |
A Real Number Set restricts the allowed value range to double precision floating point numbers.
A Time Point Set restricts to dateTime values or to truncated such values where truncation may only proceed from the least significant end, i.e. the seconds, towards the years. The interpretation of truncated values is by filling in the "default value". E.g. 2002-06-15 would be interpreted as 2002-06-05T00:00:00 local time. (If it is not sufficiently clear which local time to use in a distributed system, the use of default values for the time zone should be avoided.) In this way date values are allowed. But note that plain time values do not permit a canonical extension to dateTime values and so cannot be used.
To support time series with a regular time grid, the Time Point Set can determine its frequency from a Concept which has a valuation restriction to a Time Duration Set. The duration Values for this Concept then will determine the intervals between the available points in time. As you see, time intervals are determined by the values of two Concepts: The first to determine the starting time, the second for the duration.
A Time Duration Set restricts to duration values.
A Text Format restricts allowed characters and string length.
The activity package tries to camouflage the absence of an agreed-upon overall process model for Gesmes/CB. Therefore, it just provides the minimum which is necessary to capture the meaning of Gesmes/CB-EDIFACT but after that waits for future extensions.
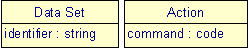 |
| Figure 8: The activity package |
The class Data Set identifies for a Party receiving data the relevant data resource, e.g. the target database. At present, there is some discussion going on to capture the precise meaning of Data Set in Gesmes/CB.
The class Action then tells about the kind of operation which should be performed on the target. The available action commands so far are "update" and "delete".
XML documents need a single document element. Moreover, current Gesmes/CB-EDIFACT is a message format and thus defines information relevant for this type of data exchange. In principle, Gesmes/CB-XML is designed to be useful also outside this traditional pattern. It should be useable also as data or structure information alone without wrapping or with a wrapping coming from a different tradition (e.g. SOAP) and serving different needs.
However, one requirement for Gesmes/CB-XML is to provide all features known from Gesmes/CB-EDIFACT so as to be useful already in the established business processes. Therefore, together with the core Gesmes/CB-XML packages data and structure, a basic enveloping functionality is proposed, too. This is the purpose of the envelope package.
The central class in the envelope package is the class Envelope, which can be used to represent the document element. An Envelope can be wrapped around data, structure, and activity objects and even around another Envelope. All of its children are optional.
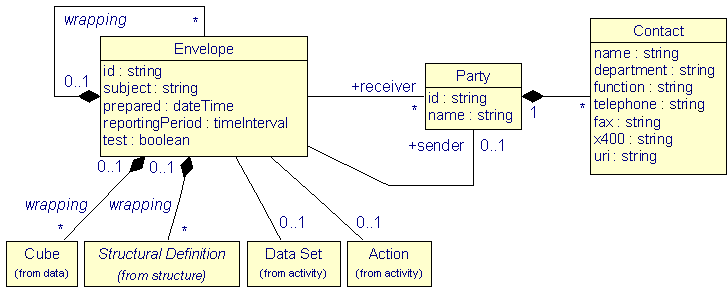 |
| Figure 9: The envelope package |
An Envelope may specify a sending Party and a number of receiving Parties together with Contact information for these.
As already mentioned, one requirement for Gesmes/CB-XML was to provide all features known from Gesmes/CB-EDIFACT. However, a couple of facets only related to EDIFACT have been dropped already in the analysis model of Gesmes/CB, most importantly the distinction between array cell and footnote section attribute.
To offer a possibility to also transport such information, though not used in XML, a simple extension mechanism is provided by the extension package. It contains a single class Extension, which can carry any additional information for particular environments. The principle is similar to the concept of TaggedValues for ModelElements in the CWM, but values may be more than just strings.
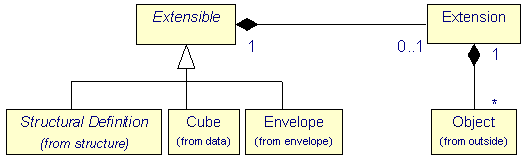 |
| Figure 10: The extension package |
The class Extension can carry an arbitrary list of objects of application specific type. Gesmes/CB applications may ignore these application-specific objects.
To aid experts who are familiar with the analysis model, this section tries to list all differences between the analysis model of Gesmes/CB and the implementation model of Gesmes/CB-XML. Most changes are merges of classes with similar structure. These merges reduce the number of used classes and hence the complexity of Gesmes/CB-XML applications. Also note that the analysis model formulates the constraints in quite detail. The implementation model for brevity does not attempt to do so.
To specify the syntactic representation of the objects of Gesmes/CB-XML, it suffices to give a syntactic expression for the classes, their properties and associations in the Implementation model.
The namespace URI for all Gesmes/CB-XML elements is www.gesmes.org/xml/2002-08-01 unless something else is stated (which is particularly the case for the Key Family specific namespaces for Cubes). All attributes are defined with the default void namespace URI. Possible exceptions from this could follow if in future activity alternatives would be chosen.
The naming convention is that all elements (and attributes anyway) which represent simple types (string, boolean, number, date, code) have lowercase names. All other elements have names with uppercase first letter and are either empty or contain only element content. There are no elements defined with mixed content. Also the Extension element (see extension implementation) should carry only element content, though in theory it could carry any.
An exception to the uppercase/lowercase naming convention may be the Value elements since their names are derived from Concept identifiers. In Gesmes/CB-EDIFACT, these identifiers are traditionally capitals only.
Another exception is the value-of element, which contains a reference to a Concept but still is written in lower case because the semantics are that it evaluates to a string derived from data.
A Value is represented by an XML attribute which holds its value as a string. The attribute's name is the Concept identifier of the evaluating Concept. The attribute's namespace is the void default.
Values for the Concepts with identifiers "TIME" and "OBS_VALUE" could be represented by the following attributes:
TIME="2002-07-26" OBS_VALUE="72.7"
A Cube is represented by an element with name "Cube". The structure selection association is implemented via the Cube's namespace. This namespace is bound to the structuring Key Family's URI. It is recommended to set the default namespace to this in the outermost Cube.
Cube nesting parallels the element nesting in XML. The Values associated with a Cube are represented as XML attributes to the Cube element.
The following shows some data concerning a time series which would be called M.TT.G in Gesmes/CB-EDIFACT. The outermost Cube binds the default namespace to http://www.ecb.int/vocabluary/2002-08-03/microbop, which is the URI for ECB's (imagined) Key Family "microbop".
<Cube xmlns="http://www.ecb.int/vocabluary/2002-08-03/microbop" FREQ="P1M" REF_AREA="TT" ITEM="G" BREAKS="Jan 2000 Redefinition of time" OBS_STATUS="A"> <Cube TIME="2000-07" OBS_VALUE="1348"/> <Cube TIME="2000-08" OBS_VALUE="1259"/> </Cube>
Note that OBS_STATUS is specified only once, in the outer Cube for all observations of the whole time series. The inheritance of Values along the nesting hierarchy allows saving space this way. The same applies to the dimension Values for FREQ, REF_AREA, and ITEM so that the inner Cubes must only specify the Values for the time dimension together with those for the observation value.
To interpret this XML fragment, it is eventually necessary to know which elements denote dimensions and which attributes. This information is present in the referenced Key Family. It would be redundant in the data file itself.
This package is the most complex one. Fortunately, exchange of multi-dimensional data is already possible with only a limited understanding of the class Key Family alone with its container classes Dimensions and Attributes. In the end, these decide whether a Concept is used as a dimension or as an attribute.
The identifier is expressed by the attribute id.
Name and description are expressed by elements name and description, of which there can be zero or more occurrences, but more than one only if all occurrences of each such element carry xml:lang attributes with different values.
The prototyping relationship is expressed by the attribute refs. This attribute contains an XPointer expression which points to the prototype. The semantics is that the referencing Structural Definition takes all values from its prototype as default. Prototyping can forward defaults along multiple generations. Also the identifier is inherited from the prototype by default if it is not specified for the referencing Structural Definition.
The context of Gesmes/CB-EDIFACT requires real prototyping only once: When a Concept is assigned by a Key Family, it refers to a globally defined Concept to take the name and description from there, but adds valuation restriction information. All other applications of the attribute refs are simple references to a previously defined element.
The XPointer expression in refs must point to a nodeset containing exactly one element. If in future the need should arise to allow multiple prototypes, this requirement may be changed. Ambiguities arising would, however, then need resolution; probably this would be achieved based on the ordering. In this case proxies for Structural Definition prototypes may be a handy tool to control the ordering.
After all name and description elements, there can be an optional Extension element.
A Code List is a Structural Definition which can also carry Codes. It is implemented as CodeList element, which after the elements specified for its superclass Structural Definition carries a Codes element, which can contain any number of Code elements.
Each Code is represented by an element Code, which has a required text element value and an optional text element description. The latter can occur zero to more times, but more than once only if occurrences are with different values for the attribute xml:lang.
The values of all Codes must be unique within one CodeList
<CodeList id="CL_OBS_STATUS">
<name>Observation status codes</name>
<Codes>
<Code>
<value>A<value>
<description>Normal value</description>
</Code>
<Code>
<value>B<value>
<description>Break</description>
</Code>
</Codes>
</CodeList>
<CodeList id="CL_OBS_CONF">
<name>Observation confidentiality codes</name>
<Codes>
<Code>
<value>F<value>
<description>Free</description>
</Code>
<Code>
<value>C<value>
<description>Confidential</description>
</Code>
</Codes>
</CodeList>
<CodeList id="CL_REF_AREA">
<name>Area codes</name>
<description>ISO two letter codes<description>
<Codes>
<Code>
<value>AT<value>
<description>Austria</description>
</Code>
<Code>
<value>CH<value>
<description>Switzerland</description>
</Code>
<Code>
<value>TT<value>
<description>Trinidad and Tobago</description>
</Code>
</Codes>
</CodeList>
A Concept is a Structural Definition which can also restrict allowed Values to a Domain. It is implemented as a Concept element, which can carry after the elements specified for its superclass Structural Definition an element Domain containing an arbitrary number of elements CodeList, TextFormat, TimePointSet, TimeDurationSet, and RealNumberSet. The range of allowed Values for this Concept then is the intersection of the allowed Values for each of the listed Value Sets.
The elements TimeDurationSet and RealNumberSet must be empty.
A TextFormat has three elements which restrict the allowed Values: The optional element ctype can contain a code "numeric" or "alphabetic" specifying the allowed character type. If ctype is missing, then no such restriction applies. The optional element length contains a nonnegative integer specifying the expected string length or, if the optional empty element varlength is present, the allowed maximum string length. If no element length is present, no length restriction applies. In the presence of named entities, the string length is measured after their expansion into the replacement text. As to escaping special characters like "<" and "&" this means the string before escaping. Also see XML syntax.
A TimePointSet can carry a frequency element, which must contain a value-of element, which must have a concept attribute containing the identifier of the Concept used as frequency. Such a Concept should have a valuation restriction to a Time Duration Set. The value-of element must not be used outside a KeyFamily element (see Key Family. This somewhat intricate nesting structure is due to the indirection involved in the relationship between time and frequency as used in Gesmes/CB.
<Concept id="FREQ">
<name>Frequency</name>
<name xml:lang="fr">Fréquence</name>
<name xml:lang="de">Frequenz</name>
<Domain>
<TimeDurationSet/>
<CodeList refs="#CL_FREQ"/>
</Domain>
</Concept>
<Concept id="REF_AREA">
<name>Reference Area</name>
<description>Geographical area of the observed phenomenon</description>
</Concept>
<Concept id="TIME">
<name>Time</name>
<name xml:lang="fr">Temps</name>
<name xml:lang="de">Zeit</name>
</Concept>
<Concept id="OBS_VALUE">
<name>Observation value</name>
<Domain>
<RealNumberSet/>
</Domain>
</Concept>
<Concept id="OBS_STATUS">
<name>Observation status</name>
<Domain>
<CodeList refs="#CL_OBS_STATUS"/>
</Domain>
</Concept>
<Concept id="OBS_CONF">
<name>Observation confidentiality</name>
<Domain>
<CodeList refs="#CL_OBS_CONF"/>
</Domain>
</Concept>
<Concept id="OBS_PRE_BREAK">
<name>Pre break observation value</name>
<Domain>
<RealNumberSet/>
</Domain>
</Concept>
<Concept id="OBS_COM">
<name>Observation comment</name>
<Domain>
<TextFormat>
<length>350</length>
<varlength/>
</TextFormat>
</Domain>
</Concept>
<Concept id="BREAKS">
<name>Series breaks</name>
<description>Overview list of historic breaks</description>
</Concept>
A Key Family is a Structural Definition which can also assign Concepts as dimensions or attributes. It is implemented as the KeyFamily element, which must carry after the elements specified for its superclass Structural Definition a uri element to determine the desired namespace for referring Cube elements. The Extension element inherited from Structural Definition follows after this. Next follows exactly one Dimensions element and finally an arbitrary number of Attributes elements. Both types of container hold an arbitrary number of Concept elements. The Key Family assigns the Concepts in the Dimensions element as dimensions, those in an Attributes element as attributes. Concept identifiers must be unique within a Key Family.
Each Attributes element in a KeyFamily must carry an attribute dimensions containing a space-separated list of identifiers of Concepts used as dimensions.
The following example shows a Key Family which defines four dimensions and six attributes. The attributes OBS_VALUE, OBS_STATUSOBS_CONF, OBS_PRE_BREAK, and OBS_COM vary with all dimensions, whereas BREAKS is constant along the TIME axis. (This is an example and should not be misunderstood as a recommendation to use such a setting when series can have many breaks.)
<KeyFamily id="MICROBOP">
<name>Exemplary Key Family</name>
<description>This is an unrealistically tiny example</description>
<uri>http://www.ecb.int/vocabulary/2002-08-03/microbop</uri>
<Dimensions>
<Concept refs="#FREQ"/>
<Concept refs="#REF_AREA">
<Domain>
<CodeList refs="#CL_REF_AREA"/>
</Domain>
</Concept>
<Concept id="ITEM">
<name>Economic item category</name>
<Domain>
<CodeList refs="#CL_ITEM"/>
</Domain>
</Concept>
<Concept refs="#TIME">
<Domain>
<TimePointSet>
<frequency>
<value-of concept="FREQ"/>
</frequency>
</TimePointSet>
</Domain>
</Concept>
</Dimensions>
<Attributes dimensions="FREQ REF_AREA ITEM TIME">
<Concept refs="#OBS_VALUE"/>
<Concept refs="#OBS_STATUS"/>
<Concept refs="#OBS_CONF"/>
<Concept refs="#OBS_PRE_BREAK"/>
<Concept refs="#OBS_COM"/>
</Attributes>
<Attributes dimensions="FREQ REF_AREA ITEM">
<Concept id="BREAKS">
<name>Breaks in series</name>
<Domain>
<TextFormat>
<length>350</length>
<varlength/>
</TextFormat>
</Domain>
</Concept>
</Attributes>
</KeyFamily>
The association to the class Data Set is represented by the element dataSetId, which carries a string. In future, the association to a Data Set may be redesigned and become more powerful once Data Sets have a stronger semantics. Actually, a clean design should also use URIs for data sets.
<dataSetId>MICROBOP</dataSetId>
The class Action is represented by a textual element action, which can take either the value "update" or "delete". In future, this element could be replaced by an enhanced mechanism to specify operations, perhaps an element called Action with first letter upper case. Also see activity alternatives.
<action>update</action>
The main element of this package is Envelope. This is a possible document element. It can carry an id attribute.
The content of an Envelope element can consist of a variety of child elements, all of which are optional and some of which can occur several times. An Envelope can contain in this ordering:
The reporting time interval ranges from the time in reportingBegin, inclusive, to the time in reportingEnd, exclusive, if both elements are present. This way, a sequence of documents can take reporting responsibility for a set of adjacent and non-overlapping time intervals.
The elements Sender and Receiver have the same type: They can have an id attribute and can contain an arbitrary number of Contact elements. Each of those can have elements name, department, and function, followed by any number of elements telephone, fax, x400, and uri in order of preference.
<Envelope id="IREF000001">
<test/>
<subject>Micro dissemination</subject>
<prepared>2002-08-28T16:36+01:00</prepared>
<Sender id="4F0">
<Contact>
<name>SIS External Hotline</name>
<department>SIS</department>
<function>Responsible for data processing</function>
<uri>mailto:sis.external@ecb.int</uri>
</Contact>
</Sender>
<Receiver id="U42"/>
<reportingBegin>2001-01-01T00:00+01:00</reportingBegin>
<reportingEnd>2001-04-01T00:00+01:00</reportingEnd>
<dataSetId>MICROBOP</dataSetId>
<action>update</action>
<Cube xmlns="http://www.ecb.int/vocabulary/2002-08-03/microbop"/>
...
</Cube>
</Envelope>
This package defines only the element Extension, which can hold any content. This provides inside Gesmes/CB-XML messages a means of transport for additional data needed by specific environments.
In general, the elements contained in Extension will not be Gesmes/CB-XML elements but from some other namespace. An application which is aware of the namespace can then use the additional information. It may occur that within one Extension there are elements from several different namespaces. This situation may (but need not) emerge if information should be supplied to a variety of different applications.
<Concept refs="#OBS_VALUE">
<name>Observation value</name>
<Extension xmlns:edifact="www.gesmes.org/xml/edifact/2002-08-01">
<edifact:conceptType>array cell</edifact:conceptType>
</Extension>
<Domain>
<RealNumberSet/>
</Domain>
</Concept>
Gesmes/CB-XML uses Concept identifiers as attribute names for Values. This fosters readability, but creates a problem when translating Gesmes/CB-EDIFACT to Gesmes/CB-XML, since the former does not restrict the allowable identifiers to valid XML attribute names. E.g. XML forbids attribute names to begin with a number and reserves those beginning with "xml".
Though the problem can be assumed to come up only in very rare cases, there is a simple solution: Use a different identifier in XML and provide the original one in an Extension for the EDIFACT environment.
<Concept id="mxl">
<name>Xion maximum length</name>
<Extension xmlns:edifact="www.gesmes.org/xml/edifact/2002-08-01">
<edifact:id>xml</edifact:id>
</Extension>
</Concept>
To aid experts who are familiar with Gesmes/CB-EDIFACT, this section tries to list all differences between the syntax implementations of Gesmes/CB-EDIFACT and of Gesmes/CB-XML. The consequences of differences in the implementation models are not repeated here, e.g. that a KeyFamily element has a uri for Gesmes/CB-XML but not so for Gesmes/CB-EDIFACT. For these see ResultDraft5 and Differences from the analysis model.
There is no established process model for Gesmes/CB yet which could be compared with the data model formulated in ResultDraft5. It is not even clear whether there is one such model which fits all existing business processes. This section does not provide one either, but it points out a few components which a process model could deal with.
Reading and parsing Gesmes/CB-XML to the objects that Gesmes/CB describes is certainly one part of processing Gesmes/CB-XML data. Due to the hierarchical nesting provided by XML and not known from EDIFACT, it is worthwhile to have a look on how to read and interpret Gesmes/CB-XML data. (Parsing Structural Definitions is straightforward and probably not worth extra consideration.)
The recommended API to process Gesmes/CB-XML is the SAX (Simple API for XML) in its current version 2 (SAX2). All major XML libraries support this open standard API. Also compare Sun's popular JAXP (Java API for XML Processing). In contrast to the DOM (Document Object Model), SAX does not require an image of the whole document to be held in memory during processing, but reads the incoming data stream piece after piece and is therefore much better suited to cope with large files.
In short, SAX translates a document into a sequence of events like "element Cube open", "attribute TIME with value 2002-07-26", "attribute OBS_VALUE with value 72.7", Cube close", and so on. The application will use each of these events to modify its internal state and possibly generate some output. In short, it can behave as an automaton.
This section specifies the reference model for how to convert the sequence of SAX events triggered by Cube data input to Gesmes/CB objects. It is inspired by pushdown automata and dictionary stacks. The main task is to support inheritance of Values by Cubes from the parent Cube. This is solved using a stack to store Values of parent Cubes. The stack depth parallels the nesting depth of Cubes when the nesting hierarchy is parsed.
Every level of the stack can hold a map mapping Concepts to Values. Processing now goes as sketched in the following:
It is easy to see that if the parsed Cube is well-formed XML, then upon exit the stack will be empty again.
At any point in time, the top map holds all the Values so far associated with the current Cube. These values can be looked up and used to build Gesmes/CB objects.
The automaton can produce output each time all attributes of a Cube have been read, i.e. after an opening Cube tag has been processed. At these times, the reader checks all attributes for which there are Values in the current top map. For each such attribute, it compares the set of dimensions for which there are Values in the map to the set of dimensions required by the attribute's attachment structure.
To set up robust checking, the parsing automaton should warn about attribute Values contained in the input which were never reported to the rest of the application. This happens if an outer Cube sets attribute Values but contains no descendants suiting the attribute's attachment structure. This checking can be implemented if the maps on the stack mark reporting of Values and delegation down a chain of maps takes the place of cloning maps. This means, if the top map does not know a Value, for a Concept, it asks the previous one, and so on until a Value is found or the bottom of the stack is reached. When a Value is registered as reported, the same chain is followed.
If the current action is delete, at each closing Cube it is checked whether the Cube contained other Cubes. If not, it is deleted. Note that this is a very basic deletion strategy. Ideas for possible future finer selection can be found in activity alternatives.
Descendant Cubes should not carry Values for Concepts that have already been set by an ancestor Cube. Actually, this could be forbidden by some data exchange contexts, see Profiles. Nevertheless, changing already set values is possible in principle. This is called overriding.
In order to maintain the correspondence between logical Cube inclusion and syntactic Cube nesting, dimension Values should never be overridden. For attribute Values, however, overriding can be a powerful technique to reduce the file size. Still some end users may not be able to process overridden Values easily. It may be best to include a configuration option for reader and writer modules which tells which restrictions should be enforced/obeyed.
To express one exceptional OBS_STATUS code, the following example uses overriding. From the perspective of inner Cubes, the Value for OBS_STATUS set for the outer Cube becomes the default value.
<Cube xmlns="http://www.ecb.int/vocabulary/2002-08-03/microbop" FREQ="P1M" REF_AREA="TT" ITEM="G" OBS_STATUS="A"> <Cube TIME="1999-12" OBS_VALUE="1448"/> <Cube TIME="2000-1" OBS_VALUE="1545" OBS_STATUS="B" OBS_PRE_BREAK="1544" OBS_COM="Redefinition of time"/> <Cube TIME="2000-2" OBS_VALUE="1467"/> <Cube TIME="2000-3" OBS_VALUE="1459"/> </Cube>
In the current use of Gesmes/CB-EDIFACT, the transactions on databases are the interchanges, which coincide with the files transferred. To be a transaction means that if an interchange is corrupted, it is rejected as a whole and none of its data is loaded into the target database.
Gesmes/CB-XML should meet all requirements of the current (not yet written) process model. It is the easiest choice to let transactions coincide with files (documents) like in Gesmes/CB-EDIFACT.
What follows is a major digression of a mathematician, please ignore it and forgive that it is here.
Gesmes/CB transactions are idempotent, meaning that twice application in sequence of the same interchange to the database leaves the database in the same state as it was after the first application.
Gesmes/CB transactions unfortunately are not commutative, which is the background behind the infamous "dependent files problem": If a file B intended to be loaded only after a file A somehow surpasses that so that A is loaded after B, A can overwrite more recent data loaded from B.
One solution to this problem is to avoid surpassing, another is to make transactions commutative. The extraction time stamp transported in the prepared element could be used to distinguish more recent data from older one and overwrite or delete only data extracted earlier. Transactions would then become commutative. However, getting rid of values loaded with an erroneous future prepared-time may need special procedures or potentially much time. Therefore, receiving applications should reliably check that the prepared value must not be in the future. (Or at least not too far ahead; a little tolerance could be necessary to avoid problems with poorly synchronised clocks.)
Not only one design of Gesmes/CB-XML can be thought of. This section gives a brief overview about possible alternative approaches and the considerations which have led to the choices made.
There are many ways to do so. A few of them are highlighted as "mixed" alternatives in the following sections.
| uniform representation | different representation |
|---|---|
|
|
The choice was made for uniform representation.
| elements | attributes | mixed | |
|---|---|---|---|
| Example | <Cube>
<REF_AREA>AT</REF_AREA>
<ITEM>S</ITEM>
<Cube>
<FREQ>P1M</FREQ>
<Cube>
<TIME>2002-10</TIME>
<OBS_VALUE>80.4</OBS_VALUE>
</Cube>
</Cube>
</Cube>
| <Cube REF_AREA="AT" ITEM="S">
<Cube FREQ="P1M">
<Cube TIME="2002-10" OBS_VALUE="80.4"/>
</Cube>
</Cube>
| <Cube REF_AREA="AT" ITEM="S">
<Cube FREQ="P1M">
<Cube TIME="2002-10">
<OBS_VALUE>80.4</OBS_VALUE>
</Cube>
</Cube>
</Cube>
|
| Arguments |
|
|
After having seen the dramatic difference in file sizes on real-world files, attributes became the choice. Reduction is about 40-50% when no overriding is used, and still 25-30% with overriding.
This would be only relevant if elements had been favoured in Transport Values in elements or attributes.
| Use Cube | Use nested Values | |
|---|---|---|
| Example | <Cube>
<REF_AREA>AT</REF_AREA>
<ITEM>S</ITEM>
<Cube>
<FREQ>P1M</FREQ>
<Cube>
<TIME>2002-10</TIME>
<OBS_VALUE>80.4</OBS_VALUE>
</Cube>
</Cube>
</Cube>
| <REF_AREA><value>AT</value>
<ITEM><value>S</value>
<FREQ><value>P1M</value>
<TIME><value>2002-10</value>
<OBS_VALUE>
<value>80.4</value>
</OBS_VALUE>
</TIME>
</FREQ>
</ITEM>
</REF_AREA>
|
| Arguments |
|
|
This would be only relevant if elements had been favoured in Transport Values in elements or attributes.
| concept-specific | generic | generic mixed | |
|---|---|---|---|
| Example | <Cube>
<REF_AREA>AT</REF_AREA>
<ITEM>S</ITEM>
<Cube>
<FREQ>P1M</FREQ>
<Cube>
<TIME>2002-10</TIME>
<OBS_VALUE>80.4</OBS_VALUE>
</Cube>
</Cube>
</Cube>
| <Cube>
<value id="REF_AREA">AT</dim>
<value id="ITEM">S</dim>
<Cube>
<value id="FREQ">P1M</dim>
<Cube>
<value id="TIME">2002-10</dim>
<value id="OBS_VALUE">80.4</att>
</Cube>
</Cube>
</Cube>
| <Cube>
<dim id="REF_AREA">AT</dim>
<dim id="ITEM">S</dim>
<Cube>
<dim id="FREQ">P1M</dim>
<Cube>
<dim id="TIME">2002-10</dim>
<att id="OBS_VALUE">80.4</att>
</Cube>
</Cube>
</Cube>
|
| Arguments |
|
|
To allow an easy entry into Gesmes/CB-XML, concept-specific (attribute) names have been chosen.
| identifiers as names | synthetic names | synthetic mixed names | |
|---|---|---|---|
| Example | <Cube REF_AREA="AT" ITEM="S">
<Cube FREQ="P1M">
<Cube TIME="2002-10" OBS_VALUE="80.4"/>
</Cube>
</Cube>
| <Cube value2="AT" value3="S">
<Cube value1="P1M">
<Cube value4="2002-10" value5="80.4"/>
</Cube>
</Cube>
| <Cube dim2="AT" dim3="S">
<Cube dim1="P1M">
<Cube dim4="2002-10" att1="80.4"/>
</Cube>
</Cube>
|
| Arguments |
|
|
Human readability would be almost completely lost if synthetic names were used. Therefore, identifiers are proposed.
IDREF and IDREFS provide a simple linking mechanism supported already by DTDs. One element in a document can refer to another element with given ID attribute. IDs must therefore be unique within the document.
XPointer is a modern linking mechanism which does not rely on a unique ID attribute and can also link to elements stored in other documents. XPointer uses the hash mark "#" to separate the document URI from the XPointer expression.
| IDREF | XPointer | |
|---|---|---|
| Example | <Concept id="FREQ"> <name>Frequency</name> </Concept> ... <Dimensions> <Concept refs="FREQ"/> </Dimensions> | <Concept id="FREQ"> <name>Frequency</name> </Concept> ... <Dimensions> <Concept refs="#FREQ"/> </Dimensions> |
| Arguments |
|
|
Note that in the attribute dimensions, XPointer makes little sense because the dimensions must be chosen from those assigned by the same Key Family that assigns the attributes.
The decisive argument for XPointer is its capability to link to other documents.
The following example shows a prototyping chain of length 2. Such a constellation cannot appear in data translated from Gesmes/CB-EDIFACT. To illustrate how XPointer can be used, the example uses three different documents scattered across three different organisations.
<!-- SDMX Project 1 vocabulary for Gesmes/CB --> <!-- http://www.sdmx.org/vocabulary/2002-08-02/gesmes.xml --> <Concept id="REF_AREA"> <name>Reference area</name> <description>Geographical area that the data refer to</description> </Concept>
<!-- BIS Concepts -->
<!-- http://www.bis.org/vocabulary/2002-08-04/gesmes.xml -->
<!-- Uses ECB's Code List CL_AREA_EE -->
<Concept refs="http://www.sdmx.org/vocabulary/2002-08-02/gesmes.xml#REF_AREA">
<Domain>
<CodeList refs="http://www.ecb.int/vocabulary/2002-08-03/gesmes.xml#CL_AREA_EE"/>
</Domain>
</Concept>
<!-- Eurostat Key Families --> <!-- http://europa.eu.int/comm/eurostat/vocabulary/2002-08-05/gesmes.xml --> <Dimensions> <Concept refs="http://www.gesmes.org/vocabulary/2002-08-01/gesmes.xml#FREQ"/> <Concept refs="http://www.bis.org/vocabulary/2002-08-04/gesmes.xml#REF_AREA"/> <Concept refs="#ITEM"/> <Concept refs="http://www.gesmes.org/vocabulary/2002-08-01/gesmes.xml#TIME"/> </Dimensions>
When specifying the domain of a Concept, Text Formats cannot be referred to like Code Lists but must be written out. It would save space in Structural Definition files if Text Formats, too, get an id and a refs attribute so as to allow prototyping relationships like for Structural Definitions.
This has not been included in the present proposal for simplicity.
XML Schema can restrict string formats by regular expressions. Particularly, these can provide all restrictions that Text Formats can define. Nevertheless, readability, simplicity, compatibility with other syntaxes, and maybe processing speed are issues which have led to the decision not to use them in Text Formats.
In future, a Read Number set could constrain the values to nonnegative, for instance. At the moment this is not possible for simplicity.
The current proposal, like Gesmes/CB-EDIFACT, gives the choice whether to update or delete on a per message basis. This means updates and deletions cannot be mixed in one message. Gesmes/CB-XML could provide a choice on a per Cube basis. This would e.g. make it possible that within one Envelope, a number of time series would be updated while another few time series were removed.
Even more fine-grained than actions per Cube would be actions per Value. However, these become only powerful in the context of Explicit action mode.
In the following comparison assume that the namespace prefix gesmes is bound to the Gesmes/CB-XML namespace URI.
| Envelope level | Cube level | Cube level using an attribute | |
|---|---|---|---|
| Example | <gesmes:action>update</gesmes:action> <Cube REF_AREA="AT" ITEM="G" UNIT="KILO"/> ... <!-- next Envelope --> <gesmes:action>delete</gesmes:action> <Cube REF_AREA="AT" ITEM="G" FREQ="P1M"/> | <Cube REF_AREA="AT" ITEM="G" UNIT="KILO">
<gesmes:action>update</gesmes:action>
<Cube FREQ="P1M">
<gesmes:action>delete</gesmes:action>
</Cube>
</Cube>
| <Cube gesmes:action="update" REF_AREA="AT" ITEM="G" UNIT="KILO"> <Cube gesmes:action="delete" FREQ="P1M"/> </Cube> |
| Arguments |
|
|
|
The concern about hindering a future process model is the decisive argument that this proposal does not define per Cube actions.
At present, two kinds of action are proposed: update and delete. However there may be a reason to consider further options.
| value | meaning |
|---|---|
| new | Register and possibly write to a new Cube. Error if the Cube already exists. |
| change | Update the information of an existing Cube. Error if the Cube does not yet exist. |
| update | Update the information. Create a Cube if necessary. |
| delete | Delete the data in a Cube and unregister the Cube. |
| replace | Combination of first delete then new. |
The additional options are exemplary (and not complete) attempts to make registration and removal of a Cube explicit and independent of filling it with data or resetting the data. The distinction between change and update could serve in simple cases as a shield against unexpected objects. Change would only be possible on time series which are already existing. However, a prerequisite to make this useful could be support for Actions on Cube level; without this it could be difficult to modify a time series by inserting new observations unless insertion does not count as change or there is a special action insert.
The deletion of a Cube primarily means the deletion of all Values stored for it. What happens to included Cubes is not clear so far. In the present understanding, though implementations could fall short of this expectation, deletion of a time series implies the deletion of all its observations i.e. all values stored for them (be it array cells or attributes in the footnote section in Gesmes/CB-EDIFACT). This could be called "recursive" mode.
On the other hand, the update of the Values of some Concept for all subcubes must be done by explicit iteration through all of them. This mode could be called "individual".
However, there is no compelling reason not to allow recursive updates and individual deletions. Actually, together with the action command, its mode could be stated to specify the behaviour concerning included Cubes.
| mode | How to treat existing subcubes |
| individual | Do not touch subcubes |
| recursive | Execute same action on all included Cubes |
| Implicit mode | Explicit mode | |
|---|---|---|
| Example 1 | <action>update</action> | <Action> <command>update</command> <mode>individual</mode> </Action> |
| Example 2 | <action>delete</action> | <Action> <command>delete</command> <mode>recursive</mode> </Action> |
| Arguments |
|
|
The mode chooses the action on subcubes already stored in the database. Cubes which are individually specified in the message are always acted on. So even in individual mode the example given in Section Cube would correctly set the Value for OBS_STATUS to A in the observations for July and August 2000; but in contrast to recursive mode, individual mode would not touch other observations of the considered time series.
Recursive updates could be a simple shortcut to set Values which are the same for a large number of Cubes. The update of OBS_CONF to free throughout a whole Data Set could be written as:
<dataSetId>MICROBOP</dataSetId> <Action> <command>update</command> <mode>recursive</mode> </Action> <Cube xmlns="http://www.ecb.int/vocabulary/2002-08-03/microbop" OBS_CONF="F"/>
If XML attributes are used to transport the action settings (also compare Actions on Cube level), this could be even shorter:
<dataSetId>MICROBOP</dataSetId> <Cube xmlns="http://www.ecb.int/vocabulary/2002-08-03/microbop" gesmes:action="update" gesmes:mode="recursive" OBS_CONF="F"/>
To transport application-specific processing information, XML defines a syntax for processing instructions. Data Set and Action can be viewed as hints to Gesmes/CB-loaders. They are irrelevant for many other applications. Therefore it could seem unreasonable to transport this information in the core data. It may be nicer to put it into processing instructions.
| Elements | Processing instructions | |
|---|---|---|
| Example | <gesmes:action>update</gesmes:action> <gesmes:dataSetId>MICROBOP</gesmes:dataSetId> | <?gesmesloader dataSetId="MICROBOP" action="update"?> |
| Arguments |
|
|
A profile is the syntactic manifestation of a restriction environment in the sense of ResultDraft5.
Not all environments need to support all features of Gesmes/CB-XML. Every data exchange context is allowed to restrict the features used in the documents exchanged. Features which are particularly prone to be restricted are:
On the other hand, some data exchange contexts may need to exchange more data than specified in the Gesmes/CB-XML proposal. In this case, the extension package or processing instructions can be used.
The use of profiles will highlight the needs of the user community and is expected to fertilise the evolution of Gesmes/CB-XML.
Adherence to the requirements of this profile makes it possible to run a mixed system using Gesmes/CB-XML and Gesmes/CB-EDIFACT. Particularly, it enforces that Gesmes/CB-XML transports all information necessary to allow reasonably easy translation into Gesmes/CB-EDIFACT.
Gesmes/CB-EDIFACT requires a few pieces of information which normally are not supplied by Gesmes/CB-XML. To transport these, dedicated elements in the Extension content are used.
The EDIFACT profile has the namespace URI http://www.gesmes.org/xml/edifact/2002-08-01. This namespace contains the following extension elements: id, conceptType and usage may appear in the Extension element of a Concept; maintenanceAgencyId and keyFamilyId may appear in the Extension element of an Envelope.
The element id is used for Aliases in the unlikely situation when the genuine identifier from Gesmes/CB-EDIFACT is not suitable as an identifier for Gesmes/CB-XML.
The element conceptType, if it appears, may only contain the fixed string array cell. It is only relevant when the Concept is assigned as an attribute and then its presence indicates that the Values for the Concept should be transported in the main ARR section rather than in the FNS section of a Gesmes/CB-EDIFACT file. See the example in extension implementation.
The element usage may only contain either mandatory or conditional. It is only relevant when the Concept is assigned as attribute and then determines whether a Value for the attribute must be present in a stable database when there is a Value for the first array cell (which is the observation value). See the example in extension implementation.
Both elements, keyFamilyId and maintenanceAgencyId, have string content; the content is an identifier. This identifier codes a reference to the Key Family used in successive Cubes or to its maintenance agency, respectively. Note that both information items are redundant in the sense that both can be inferred from the namespace URI of the used Cube elements. However, it may be too difficult for applications to extract this information from this URI. Practical use will show whether these extension elements are actually useful.
<Envelope id="IREF000001" xmlns="http://www.gesmes.org/xml/2002-08-01" xmlns:edifact=http://www.gesmes.org/xml/edifact/2002-08-01">
<subject>Micro reporting June 2002</subject>
<prepared>2002-08-13T17:44+01:00</prepared>
<Sender id="TT2"/>
<Receiver id="4F0"/>
<Extension>
<edifact:maintenanceAgencyId>ECB</edifact:maintenanceAgencyId>
<edifact:keyFamilyId>MICROBOP</edifact:keyFamilyId>
</Extension>
<dataSetId>MICROBOP</dataSetId>
<action>update</action>
<Cube xmlns="http://www.ecb.int/vocabulary/2002-08-03/microbop">
...
</Cube>
</Envelope>
Gesmes/CB-EDIFACT specifies an ordering relationship of Concepts assigned as dimensions or array cells in a Key Family. The convention for translation is to use the sequential ordering of the children of the Dimensions and Attributes elements.
Translation from Gesmes/CB-XML to Gesmes/CB-EDIFACT requires consideration of some restrictions.
Gesmes/CB-EDIFACT defines upper bounds for the occurrences of all information items. E.g. there may only be up to three Contacts in the Sender and up to five communication channels for each of them. For details see the documentation on Gesmes/CB-EDIFACT to be found at http://www.ecb.int/stats/gesmes/gesmes.htm.
Generally, Gesmes/CB-EDIFACT accepts only limited string lengths. These vary according to the function of the string, e.g. whether it is an identifier or an attribute Value. For details see again the documentation on Gesmes/CB-EDIFACT.
Also note the surprising constraint that Gesmes/CB-EDIFACT cannot transport attribute values with 350 or more successive whitespace characters.
The Contact function may contain only one of four strings:
The Contact URI may only use the mailto: protocol.
The use of URIs is new to Gesmes/CB. Since Cool URIs don't change, considerable care should be taken by maintenance agencies and also the Gesmes/CB reference organisation when defining namespace URIs. Having longevity established as the foremost objective when designing URIs, it should also be easy to use for humans. To sum up: The URIs should be logical, independent of organisation structure (prone to change), and easy to recall for humans.
This section proposes a pattern to use when setting up Gesmes/CB-XML maintenance agency sites. If the Gesmes/CB user community accepts these or similar best practices, it may become significantly simpler to install and maintain data exchange contexts.
It is assumed that an institution owns a web-site or at least a URI with a protocol like http: that models a directory tree; i.e. https: and ftp: are fine, mailto: will not work that well. All URIs of the organisation are then in its URI tree.
The pattern proposed here to define directory URIs is as follows. The Gesmes/CB reference organisation uses:
| http://www.gesmes.org | Root URI for the syntax-independent data model. |
| http://www.gesmes.org/xml | Root URI for XML syntax. |
| http://www.gesmes.org/xml/edifact | Root URI for the EDIFACT profile in XML syntax. |
All root URIs are then extended by a date to allow versioning.
Similarly, a maintenance agency with, for example, the homepage URI http://www.sdmx.org, would use:
| http://www.sdmx.org/vocabulary | Root URI for business vocabulary. |
| http://www.sdmx.org/vocabulary/2002-08-02 | Root URI for business vocabulary in a particular version. |
| http://www.sdmx.org/vocabulary/2002-08-02/bop | Root URI for a business term in a particular version. The business terms used in Gesmes/CB-XML are essentially Key Families but there is no reason not to exhibit also Code Lists. |
In principle, Gesmes/CB-XML uses a Key Family's URI only to bind the namespace for Cubes structured according to the Key Family. However, when the URI actually can be dereferenced, this can be exploited further for increased benefit of users of Gesmes/CB-XML. So the URIs dealt with in the section Directories should be populated with files.
The URI of a Key Family can be seen as pointing to the Key Family's homepage. Business terms like Code Lists could get similar URIs but let us focus on Key Families here. Such a homepage should contain the following files:
| (no filename) | Redirect to index.html. This would be a starting page to find documentation about the Key Family for humans and/or applications, particularly links to the following files in the directory. |
| gesmes.xml | The Gesmes/CB-XML representation of the Key Family. This can contain in refs attributes also XPointer links to other files to find Code Lists and Concepts from shared locations. |
| gesmes.html | For the web-user's convenience, an HTML-representation of the Key Family. It may be the result of simply applying a style sheet to gesmes.xml or may have added fancy features. Where gesmes.xml contains references to Structural Definitions in other Gesmes/CB-XML documents, gesmes.html would typically contain hyperlinks to the corresponding HTML versions of these documents. |
| gesmes.xsd | An XML Schema for Gesmes/CB-XML data files which contain data for the Key Family. Such a schema is very useful for applications which are only aware of one Key Family. They can use this schema to perform standard validation of data files. |
| gesmes.xsl | An XSLT style sheet for Gesmes/CB-XML data files which contain data for the Key Family to convert them to HTML. XML data files could reference this style sheet in order to enable users to view data files with their browser like an HTML page. This could prove very practical, since cross-linking may be possible. |
Look at the exemplary URI
http://www.sdmx.org/vocabulary/2002-08-02/bop/gesmes.xml
Read from left to right, this is SDMX's understanding as of 2 August 2002 of what bop means formulated in terms of the Gesmes/CB data model and in XML syntax. Longevity of the naming schema is achieved by putting the technology dependent part to the far right. If in future a different innovative data format would be used, the URI could become
http://www.sdmx.org/vocabulary/2022-12-24/bop/gosmos3.xom
for instance, and still be consistent. Of course, if the web-site itself changes its address, then too bad.
To aid maintenance agencies, www.gesmes.org as the Gesmes/CB reference organisation would make available in the Gesmes/CB-XML namespace URI on its site a similar directory containing:
| (no filename) | Redirect to index.html. As a starting page to find documentation about Gesmes/CB-XML for humans and/or applications, particularly links to the following files in the directory. |
| gesmes.xsd | An XML Schema for Gesmes/CB-XML Structural Definitions files. |
| gesmes.xsl | An XSLT style sheet to translate Gesmes/CB-XML Structural Definitions files to HTML. XML Structural Definitions files could reference this style sheet in order to enable users to view data files with their browser like an HTML page. |
| gesmes2xsd.xsl | An XSLT style sheet to translate Gesmes/CB-XML Structural Definitions files into an XML Schema like gesmes.xsd in maintenance agencies' sites for validating data files. |
| gesmes2xsl.xsl | An XSLT style sheet to translate Gesmes/CB-XML Structural Definitions files into an XSLT style sheet like gesmes.xsl in maintenance agencies' sites for viewing data files. |
There are a number of issues to be addressed in future discussion. This document tries to provide a collection of these, possibly with links to the group cbXML.